
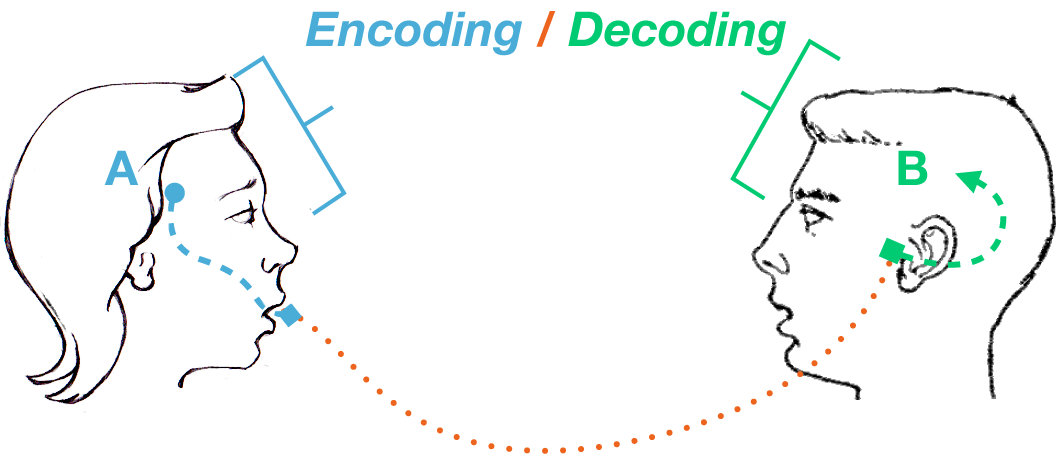
وقتی شما، کاراکتری را در یک برنامه ویرایش متن یا اپلیکیشن وب قرار میدهید، این کاراکتر با استفاده از مجموعهای از اعداد، کدگذاری میشود که به اصطلاح به آن یونیکد (UNICODE) گفته می شود. زمانی که مرورگر، محتوای اپلیکیشن وب را دریافت میکند، این اعداد رمزگشایی شده، بر روی نمایشگر نشان داده میشوند. محوریت اصلی این مقاله هم دقیقا همین اعداد و نشانه ها و بررسی پرسش یونیکد چیست و چگونگی رمزگشایی آن است و در نهایت به مبحث utf-8 پرداخته خواهد شد و به این پرسش که UTF-8 چیست پاسخ خواهیم داد.
UNICODE یا یونیکد چیست
در پاسخ به پرسش unicode چیست ؟ بایستی گفت حروف، اعداد و علائمی که در اپلیکیشنهای وب استفاده میشوند، به همان شکلی که شما آنها را میبینید، در کامپیوتر مدیریت نمیشوند. کامپیوترها فقط با اعداد سروکار دارند. پس این حروف و کاراکترها، باید به مجموعهای از اعداد ۰ و ۱ تبدیل شوند تا مدیریت آنها آسان باشد. لذا استاندارد واحدی باید وجود داشته باشد. بر همین اساس، مشخص میشود که هرکدام از این اعداد چه کاراکترهایی را نمایش دهند و چگونه بر روی دیسک ذخیره شوند. به این استاندارد اصطلاحا UNICODE گفته می شود.

در واقع یونیکد، مجموعهای از charset یا کاراکترست با اعداد منحصر به فرد است، که به آن در اصطلاح پوینت کد (Point Code) گفته میشود. هر پوینت کد، کاراکتر واحدی را نمایش میدهد. بر این اساس، استاندارد یونی کد سه نوع روش کدگذاری را تعیین میکند، و به یک کاراکتر اجازه میدهد در داخل یک یا چند بایت کدگذاری شود (یعنی در ۸ یا ۱۶ یا ۳۲ بیت).
باید بدانید که کاراکتر در علوم کامپیوتر برابر با حروف و اعداد در سیستم نوشتاری است در ادامه این مقاله از گروه تولید محتوای ایران هاست ( ارائه دهندهی تبلیغات گوگل ادوردز با امکان مدیریت و شارژ اکانت ) بیشتر در این باره توضیح خواهیم داد.
![]()
انکودینگ یا encoding چیست؟
اگر بخواهیم در یک جمله به شما encode را توضیح دهیم، بایستی گفت تبدیل داده ها بصورتی که سیستم توانایی خواندن و استفاده از آن را داشته باشد، encoding گفته می شود. مثلا همین نمایش کاراکتر های خاص در وب نوعی انکدینگ به حساب می آید. در واقع encoding ، رمزگذاری فرآیند تبدیل داده ها به فرمت مورد نیاز برای تعدادی از نیازهای پردازش اطلاعات است، از جمله:
- تدوین برنامه و اجرای آن
- انتقال داده ، ذخیره سازی و فشرده سازی / رفع فشار
- پردازش داده های برنامه ، مانند تبدیل پرونده
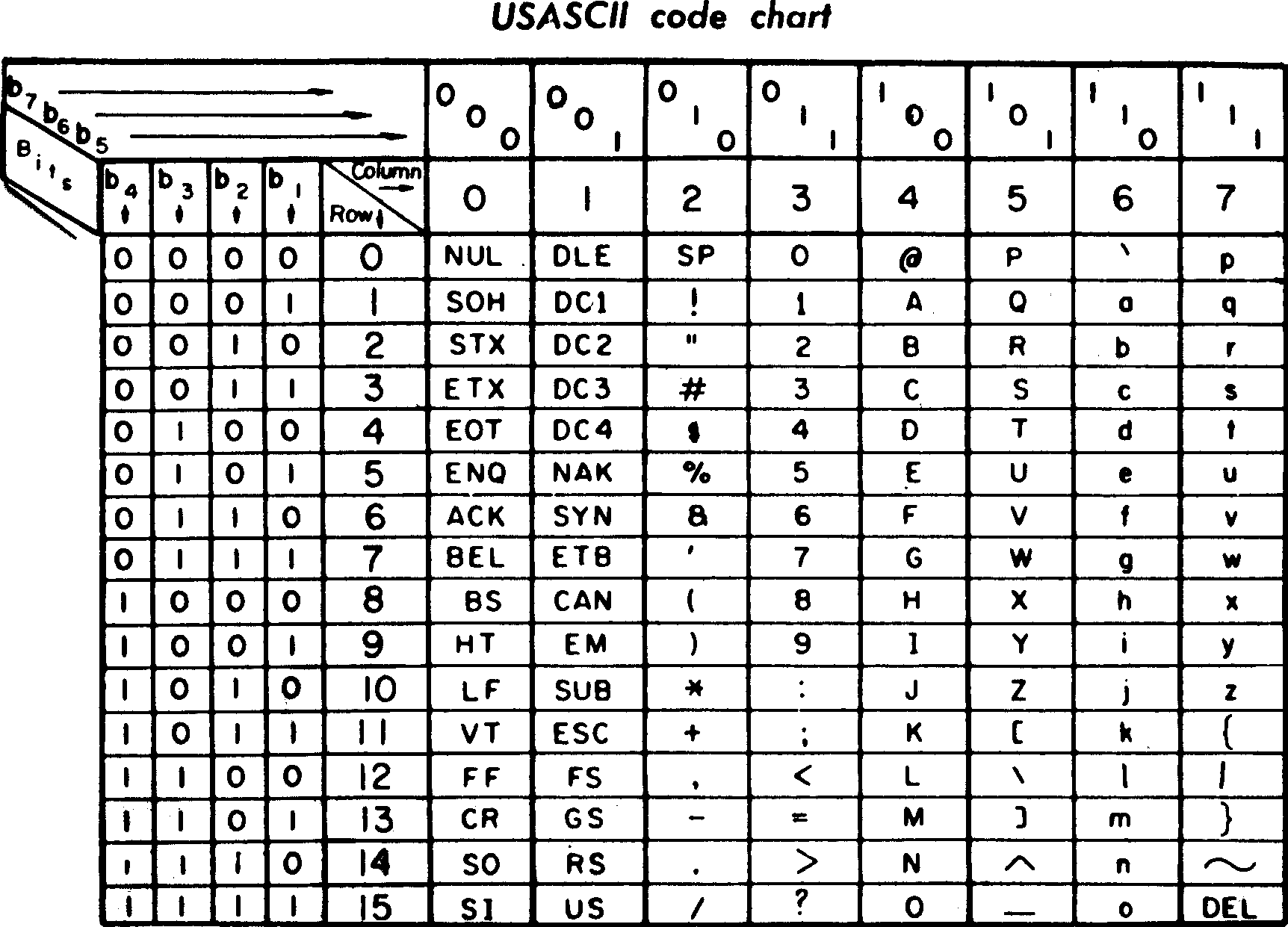
تعریف کد اسکی یا ASCII
برای استاندارد انکدینگ، که در بالا به آن اشاره کردیم، انجمن استانداردهای آمریکا در سال ۱۹۶۰ یک روش کدگذاری ۷ بیتی، با نام ASCII که مخفف عبارت American Standard Code for Information Interchange است را معرفی کرد. در آن زمان، مجموعه کاراکترهای ASCII شامل ۱۲۸ کاراکتر (۷ بیت) که بیشتر مخصوص زبانهای لاتین بود، تعریف گردید.
![]()
در دهه ۱۹۸۰، تصمیم بر این شد که در مجموعه کاراکتر ASCII به جای ۷ بیت، از یک بایت کامل (یعنی ۸ بیت)، برای کدگذاری استفاده شود. لذا تعداد کاراکترها به ۲۵۶ عدد میرسید. بر این اساس، کاراکترهای بعد از ۱۲۷ تا ۲۵۵ نیز، به عنوان کدهای رزرو شده در نظر گرفته شدند و زبانهای دیگر، عموما در این بازه قرار میگرفتند.
اما در این محدوده بین زبانهای مختلف، استاندارد واحدی وجود نداشت و هر زبانی، کد مختصِ الفبایِ خودش را نشان میداد. به عبارت دیگر کد ۲۰۰ در یک زبان، حرف متفاوتی را در زبان دیگر برمیگرداند. در نتیجه، نیاز به استاندارد واحدی بود تا ضمن سازگاری با تمامیزبانها، کدهای منحصر به فردی را برای هر کاراکتر در نظر بگیرد.
تلاش برای ایجاد مجموعه کاراکتر های واحد برای زبان های مختلف
در ابتدا دو تلاش مستقل برای ایجاد مجموعه کاراکترهای واحد صورت گرفت.
۱- ISO-10646
“ISO-10646” پروژه سازمان بینالمللی استاندارد بود
۲-Unicode
پروژه بعدی Unicode نام داشت که توسط کنسرسیومی به نام کنسرسیوم یونیکد سازماندهی میشد.
داشتن دو نوع استاندارد مطمئنا چیزی نبود که بتوان آن را استاندارد واحدی نامید. ISO و Unicode این مطلب را دریافتند و تصمیم گرفتند در سال ۱۹۹۱ به یکدیگر بپیوندند.
تفاوت کد اسکی با یونیکد
Unicode و ASCII هر دو از استانداردهایی هستند که برای Encoding متن ها استفاده می شوند. در واقع این دو استاندارد در برنامه نویسی باعث می شوند تا بین زبان های مختلف ارتباط برقرار شود.
روش های کدگذاری Unicode چیست ؟
همانطور که در بالا اشاره شد، یونیکد به سه روش کدگذاری را انجام می دهد که عبارتند از:
- UTF-16
- UTF-8
- UTF-32
در واقع UTF مخفف عبارت Unicode Transfer Format و به معنای فرمت انتقال یونیکد است. در ادامه به این پرسش پاسخ خواهیم داد که UTF-8 چیست
تفاوت این روشهای کدگذاری، در نحوه ارایه حروف، اعداد و علائم، بین زبانهای کشورهای مختلف است. به طوری که نحوه ارایه کاراکترها در یک کشور با کشور دیگر متفاوت است.
utf-8 چیست؟
در پاسخ به پرسش utf-8 چیست بایستی گفت، اولین بار بطور رسمی در کنفرانس USENIX در سال ۱۹۹۳ معرفی شد. در حال حاضر UTF-8 ، غالبترین روش کدگذاری کاراکتر در میان وبسایتها است. Utf-8، روشی است که قابلیت کدگذاری تمامیکاراکترهای موجود، و یا به عبارتی تمامی کد پوینتهای موجود در یونیکد را دارد.
UTF-8، همانطور که گفته شد الگوریتمی است که اعداد مربوط به پوینتکد را به باینری تبدیل میکند، بطوری که بتوان آنها را بر روی دیسک ذخیره کرد.
برای نمونه در ابتدا به یک نرمافزار، کدی شبیه به کد زیر را ارایه میکنیم :

۱۱۰۱۰۰۰ ۱۱۰۰۱۰۱ ۱۱۰۱۱۰۰ ۱۱۰۱۱۰۰ ۱۱۰۱۱۱۱
نرم افزار میداند که داده ارایه شده یک رشته یونیکد بر مبنای UTF-8 است و باید آن را بصورت متن به کاربر نشان دهد. در قدم اول، بر اساس روش رمزگشاییUTF-8 ، مقدار باینری آن را به اعداد تبدیل میکند و در نهایت این کدها را بر میگرداند :
۱۰۴ ۱۰۱ ۱۰۸ ۱۰۸ ۱۱۱
نرم افزار میداند که این، یک رشته یونیکد است. نرمافزار فرض میکند که هر عدد یک کاراکتر را بر میگرداند. در این هنگام، هر عدد را به کاراکتر متناظر با آن ترجمه میکند، نتیجه کلمه “Hello” است.
همانطور که گفته شد، UTF-8 طول متغیری دارد و میتواند تا ۴ بایت افزایش یابد، ولی کاراکترهای اصلی (ASCII) را میتواند با یک بایت نمایش دهد. چون طول متغیری دارد باید روشی وجود داشته باشد که مشخص شود، کاراکتر از یک بایت یا چند بایت ساخته شده است.
لذا، UTF-8، در بایت اول تنها از ۷ بیت آن استفاده میکند و بیت اول آن برای این هدف کنار گذاشته شده است.
بنابراین به نسبت گفته شده، ۲ بایت درUTF-8 (۱۱^۲ = ۲۰۴۸ کاراکتر یا کد پوینت) ۱۱ بیت را ارائه میکند، ۳ بایت در UTF-8 از ۱۶ بیت پشتیبانی میکند (۱۶^۲ = ۶۵,۵۳۶) و ۴ بایت نیز، ۲۱ بیت (۲۱^۲ = ۲,۰۹۷,۱۵۲) را فراهم میکند.
با این وجود تعداد کاراکتر های مجاز در UTF-8 در حال حاضر”۲۰۹۷۱۵۲” است، در حالی که آخرین نسخه UNICODE 6.0 که در سال ۲۰۱۰ ارایه شد، تنها کمی بیش از صدهزار کاراکتر یا پوینت کد را تعریف میکند.
UTF-8، از دیگر روشهای استفاده شده در متن وبسایتها، در حالِ حاضر پیشی گرفته است و در سال ۲۰۱۰ نزدیک به ۵۰ درصد، و در جولای سال ۲۰۱۵ به ۸۴ درصد رسیده است.
مزایای utf-8 چیست؟
- UTF-8 تنها الگوریتم موجود برای XML است که نیازی به BOM یا شاخص کدگذاری ندارد.
- UTF-8 و UTF-16 روشهای کدگذاری استاندارد برای متون یونیکد در فایلهای کد utf-8 در html هستند، و UTF-8 پرکاربردترین آنها است.
- رشته کد UTF-8 میتواند همانند یک الگوریتم اکتشافی ساده به نظر برسد. این ویژگی که بیشتر روشهای کدگذاری آن را ندارند، به UTF-8 اجازه میدهد نوع کدگذاری را تشخیص دهد. با این روش، بدون اینکه نیازی به افزودن بیت به آن داشته باشد، از خطاهای معمولی که هنگام تغییر یک سیستم به یک انکدینگ پیشفرض روی میدهد ، اجتناب خواهد کرد.
- UTF-8 میتواند هر نوع کارکتر یونیکد را کدگذاری کند. فایلها را، بدون اینکه مجبور باشند فونت درستی را انتخاب کنند، با اسکریپتهای متفاوت به درستی نمایش دهد.
- UTF-8، از کدهای ۰-۱۲۷ برای کاراکترهای اسکی استفاده میکند. این کد بر خلاف دیگر سیستمها، نیازی به افزایش حجم برای نشان دادن کدهای اسکی ندارد. این بدین معنی است که در تمامی نرمافزارهایی که از کاراکترهای ۷ بیتی پشتیبانی میکنند، قابل پردازش است.
- UTF-8 قابلیت خود هماهنگی دارد : اگر بایتها به دلیل خطا یا مشکلی از بین بروند ، میتوان شروع کاراکتر معتبر بعدی را پیدا کرد و پردازش را ادامه داد.
- کدگذاری درUTF-8 ، نیازی به عملیات ریاضی مانند ضرب و تقسیم ندارد و از عملیات ساده بیتی استفاده میکند.
معایب utf-8
- کاراکترهایی که در روشهای کدگذاری دیگر مانند ISO-8859 و WINDOWS-1252 میتوانند با یک بایت نشان داده شوند، در UTF-8 باید با دو بایت نمایش داده شوند.
- یک مبدلUTF-8 ، که با نسخههای کنونی استاندارد، سازگار نیست. ممکن است یک عددشبیه به UTF-8 متفاوت را دریافت کند و آن را به خروجی یونی کد تبدیل کند.
- متون کدگذاری شده توسط UTF-8، به جز برای کاراکترهای ASCII، حجم بیشتری نسبت به سیستمهای دیگر اشغال میکند.
- در UTF-8، این امکان وجود دارد که یک کاراکتر را از وسط یک رشته کد بشکافید. اگر دو قطعه جدا شده نتوانند بعدا در توالی هم قرار بگیرند، این امر ممکن است باعث شود آن رشته کد، نامعتبر شود.
- بسیاری از نرمافزارها مانند ویرایشگر متن، UTF-8 را نمیتوانند نمایش دهند یا ترجمه کنند، مگر اینکه آن متن با یک BOM شروع شود.
- UTF-8، نسبت به یک انکدینگ چند بایته، که تنها برای یک زبان خاص طراحی شده است، حجم بیشتری میگیرد. کدگذاری زبانهای آسیای شرقی نیاز به دو بایت برای هر کاراکتر دارند، در صورتی که در UTF-8، به ۳ بایت نیاز است.

چرا UTF-8 بسیار محبوب است؟
دلیل آن در این حقیقت نهفته است که تمامی کاراکترهای اسکی، تحت یک بایت تنها، در UTF-8 قرار میگیرند. لذا هم کاملا با نسخههای قدیمی سازگار است و هم برای زبان انگلیسی و دیگر زبانهای اروپایی، از نظر حجم بهینهتر است.
به دلیل اینکه زبان انگلیسی و اروپای غربی، بیشترین استفاده را در میان کاربران اینترنت دارند، بنابراین UTF-8 به سرعت تبدیل به محبوبترین یونیکد، در محیط وب شد.
تفاوت ansi و utf 8 چیست
ANSI و UTF-8 هر دو فرمت رمزگذاری هستند. ANSI یک قالب بایت رایج است که برای رمزگذاری الفبای لاتین استفاده می شود. در حالی که ، UTF-8 یک فرمت یونیکد با طول متغیر است (از ۱ تا ۴ بایت) که می تواند تمام شخصیت های ممکن را رمزگذاری کند.
تفاوت UTF-16 و UTF-32 با utf-8 چیست
در بیان اینکه تفاوت بین UTF-16 و UTF-32 با utf-8 چیست این نکته را باید گفت که UTF-8، نیاز به فضای اضافی برای ذخیره کد ASCII زبان انگلیسی ندارد، و بیشتر زبانهای غرب اروپا را پوشش میدهد. برای زبانهای چینی، ژاپنی و کرهای نیز، به ۵۰ درصد فضای بیشتر نیاز دارد، و برای زبان یونانی و سریلیک، به ۱۰۰ درصد فضای اضافهتر نیازمند است.
در مقابل، UTF-16 به فضای اضافه برای زبان های چینی، ژاپنی، کره ای نیاز ندارد، ولی برای زبانهای اَسکی و زبانهای غرب اروپا ، یونانی و سریلیک نیاز به ۱۰۰ درصد کل فضای خود دارد.
UTF-32 ، طول ثابتی دارد و بیشترین فضا را اشغال میکند.
سخن آخر
با توضیحات ارایه شده در مورد یونیکد چیست و همینطور utf8 چیست، میتوان دریافت چرا UTF-8 پرکابردترین روش کدگذاری در فضای وب است و محبوبیت آن نیز روزبهروز در حال افزایش است. این مورد حتی در هاست ایمیل نیز مهم است بطوری که عدم انتخاب استاندارد مناسب، می تواند باعث ناخوانا بودن ایمیلهای شما شود. در نظر داشته باشید با وجود وبسایتهای چند زبانه، سازگاری وب سایت با استانداردهای موجود، مهمترین عاملی است که در انتخاب نوع روش کدگذاری خود باید آن را در نظر بگیرید.
ممنون از مطلب خوبتون
خیلی عالی بود ممنونم ازتون
سلام
در مورد نکته ای میخواستم بدونم که این درست برای تبدیل به SAP ECC 6.0 باید uicode رو تبدیل کنیم؟
ممنون از مقاله خوبتون
سلام
خیلی عالی بود مخصوصا قسمت اول مقالتون که درباره encode نوشته بودید.
پاسخ همه ی سوالاتم utf چیست انکودینگ چیست یو تی اف ۸ چیست در این مقاله بود ممنونم
عالی
خیلی جامع بود
مرسی
سلام
ممنون از مطلب خوبی که منتشر کردید. فقط یک مشکل وجود داشت و آن هم اینکه تصاویر باز نمیشد و اگر این مشکل را رفع نمایید ممنون میشوم. برای درک کامل متن بودن تصاویر لازم بود.
با تشکر
باسلام و وقت بخیر؛
باتشکر از حسن توجه شما، تصاویر اصلاح شدند و در حال حاضر امکان مشاهده آنها را دارید.